
初窥人工智能时代(科普向)

初窥人工智能时代(科普向)
家乡“ChatGPT”、“OpenAI”、“通用人工智能”,“大模型”,“提示词工程”,“AIagent”,“LangChain”,“Token”,这些人工智能行业的黑化在2023这个普通又神奇的年份里不断冲刷着大家的认知。相信同学们对这些热门话题都有一定的了解。但到底什么是大模型?国内外发展状况是怎样的?在人工智能火热的今天我们将如何自处?本文将会避免专业晦涩的词汇,从学生的角度,分四个方面为同学们一一讲清楚这些问题。
大模型按照功能可分为NLP大模型、CV大模型、科学计算大模型和多模态大模型。
CV(计算机视觉)方向:人脸识别、物体检测等,典例如腾讯的PCAM模型。
科学计算方向:主要用于解决科学领域的计算问题,如华为的盘古气象模型。
多模态方向:比较火的有文生图,文生音,典例如StabilityAI的stablediffusion。
NLP(自然语言处理)方向:我们所熟知的OpenAI的GPT系列模型就是这个方向,具备强大的语言理解和生成能力。

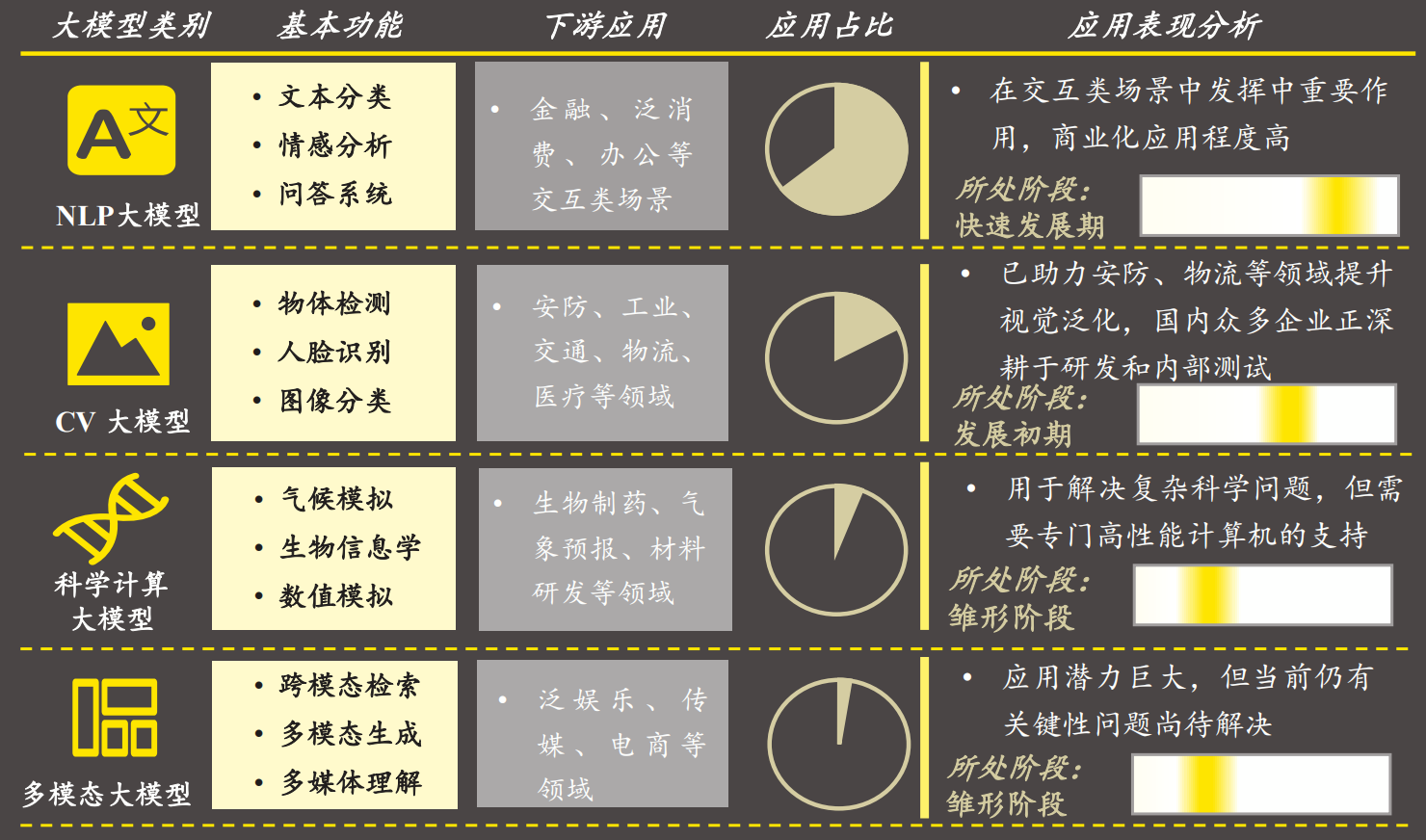
本文主要对NLP方向的模型进行科普,下文提到的大模型都是NLP方向的大模型。
你可以把大模型简单的理解为一个成绩普通的大学本科毕业生的大脑,这颗大脑因为多年在校学习的经验,理解了大量人类的通用知识,比如说基础的算数能力,基础的推理能力,了解基础的物理法则,知道人类的发展历史,甚至会说谎。
而大模型在这些方面其实也一样,AI大模型本身是生成模型,它的目标仅仅是根据前面的输入来预测词元(Token)。所以说大模型的本质是计算概率。本质上它并不关心你输入的是什么,也无意回答你的问题,它的目标只是为了让文本看起来完整。这就导致了人们所说的大模型的幻觉问题。
举个例子来说,你完全可以让大模型来描述你的早餐,尽管它并没有见过你,更不知道你早餐吃了什么,但并不影响它能很清晰的描述你吃了什么。这是因为它读了大量的wiki文档,人类的web网页,人类曾经写过的小说。这些资料里边,描述早餐就是这样描述的。所以它就按照概率,写出了这样一段文本。所以大模型才经常会发出一些不存在的URL地址,引用一些不存在的论文。仅仅是因为URL和论文在海量的资料里边看起来就是这样的。这就是大模型的幻觉。
有在同学可能会想,这跟大学生的大脑也不一样啊?其实是一样的。比如说你要上课了,但是你没有交作业。老师会问你的作业呢?你会从自己的知识库里边搜索怎么回答比较合理:我忘记写了;昨天沉浸于帮老奶奶过马路耽误了写作业的时间;我的作业被哈吉米吃了;我的作业发生了量子隧穿消失了;我也还在找。根据概率挑一个答案来回复老师:我的作业被哈吉米吃了。对你的老师来说,这其实是一种幻觉。你的老师会问:合理吗?从理论上来说,这个可能性也是存在的,但是通过老师多年的执教经验来判定,大概率是假的。这是一个人类分辨出幻觉的例子。而像刚才早餐的描述,我自己知道它是假的,但第三方却很难分辨这段话的真假,这就是幻觉问题的危害。
在人工智能时代,谁是最大的赢家呢?
无论从技术角度还是财富增长的角度来看,人工智能时代最大的红利获得者似乎是借着AI的东风,实现了财富自由的创业公司创始人。但有句老话说的好,淘金的不一定赚钱,卖铲子一定赚钱,如果AI公司是淘金客,那NVIDIA就是卖铲子的。现在去查NVIDIA的官网,标题已经变成了“人工智能计算领域的领导者”,可见NVIDIA在人工智能浪潮中的获利。
那么为什么AI发展非GPU不可呢?CPU和GPU最大的差别是CPU一般只有8-16个核心,而一个GPU却有上千个核心。有个经典的例子:CPU是一个科研大牛组成的小组,GPU是几千个只会做加减乘除的小学生,好巧不巧进行大模型训练就是计算成千上亿个简单的加减乘除,因此GPU训练模型远远快于CPU。对于这一点本人深有体会,本人电脑显卡3060,在做一个小模型训练项目的时候,和同学的4060性能差了3倍以上。而且显卡是真的贵,游戏级别的显卡3060现在报价2000左右,专业级的如A100一张成本9000卖17万左右,而且这还供不应求。这一点从Sam Altman多次在公开场合的言辞中也可以看出,在过去一整年里,他几乎都在抱怨英伟达GPU短缺,导致OpenAI的GPU供应严重受限的问题。
有意思的是,随着OpenAI估值逼近1000亿大关,Sam Altman不再满足于血拼谷歌和苹果,而是直接向算力霸主英伟达开战。据知情人士透露,Sam Altman正在积极向全球投资者寻求庞大的资金支持,以便建立一座AI芯片制造厂。其中就包括阿布扎比的G42和日本的软银集团,尤其是在与G42的谈判中,涉及金额就已经接近80亿到100亿美元国内外产业现状。
首先叠个甲,学长并不是什么行业大牛,对市场的认知难免有所错漏与疏忽,下面的认识仅仅基于个人观点,如有不严谨之处,欢迎通过邮箱与我共同探讨。
从总体来看,国外基本上已经是魏蜀吴三分天下,国内目前还处在群雄割据时代。
国外三分天下的分别是OpenAI(ChatGPT), Anthropic(Claude)和Google(Gemini)。相比于国内,国外目前无论是投资还是人才密度都很集中,基本上都在这三家里。形成这种局面的主要原因是OpenAI的技术遥遥领先,同时微软签了独家协议,其他公司比如Google,Amazon等不能投OpenAI,自研又太慢,所以只能投资老二,也就是Anthropic。Anthropic是由OpenAI的前员工创立的,据说这波人当时是觉得OpenAI被微软投资了之后变的越来越不Open了,于是转头创立了新的公司Anthropic。这里面很多人是OpenAI崛起路上的核心骨干,比如Dario Amodei参与过GPT-2和GPT-3的研发,Tom Brown是GPT-3的第一作者。这波人是真正知道大模型秘密的人,所以Anthropic更像是OpenAI的小姐妹,Google和Amazon等公司发现心中的白月光OpenAI已经被微软霸占了,心里那一着急,所以只能去追求白月光的妹妹Anthropic。Anthropic另开炉灶的出发点也许是好的,但是从最后的结果来看,Anthropic并没有比现在的OpenAI更加Open。哼!万恶的资本。
Google呢,是第三家,作为上一个时代的领导者,还是有些不服气。在投资的同时,自研也没有停止,终于在23年底勉强说自己追平了半年多以前的OpenAI。以上就是目前国外AI公司的现状。商业公司三分天下,开源被商业公司吊打。
除了这些公司以外,马斯克的X.AI也比较有潜力,马斯克的融资能力可比Sam Altman强的多。再一个就是财大气粗的苹果,苹果肯定是想拥有一个更加智能的Siri的。但是目前没发现什么大动作,可能内部也在尝试,如果尝试结果不太理想,后续苹果投资谁可能比较关键。Meta感觉光内耗了,精神领袖杨立昆看不起GPT,然后据说算力分配内斗的厉害,只能靠开源来维持一下江湖地位。但是还是很感谢Meta开源的Llama。再卷几年,估计就像操作系统一样,最后也就剩下两到三个公司。目前看上面3个公司的赢面还都挺大。小公司就不要想着做通用大模型了,国外基本上已经放弃。反而在一些细分领域做出有特色的产品,抢占了一些市场。比如Character AI,创始人是Transformer的作者之一,目前日活用户百万。主打一个赛博恋爱,找一个AI老公和AI老婆,你的世界你做主。
国内处境就比较难了。第一个困境,就是显卡不够,老美禁售。第二个困境是在显卡资源有限的情况下,国内公司并没有出现明显的技术领军公司,谁都想干,让投资和计算资源更加的分散。第三个是中文的高质量语料比起英文确实是有点少,互联网上大部分都是喷子和软文。最后,除了上面那3个公司的几百个人知道大模型研发的核心机密,其他国家和地区的人才在这波浪潮中完全落后了,这也没有办法,前沿科技总是掌握在少数人手中。现在国内的状态,就有点像是老外的曼哈顿计划已经有一定成果了,我们呢,是从头研发原子弹。没有盗火者,只能自己努力。一句话总结就是商业和开源群雄并起,目前没有拉开显著差距。
如果从硬件条件来看,最有前途的可能是字节(云雀)。字节之前囤了不少卡,入场券已经拿到了。但是不知道字节有没有真正了解大模型的人才,不然卡多也没用。之前传言从 OpenAI 挖了个人,但不知道真假。
阿里(通义千问)和百度(文心一言)由于有云服务,属于既卖铲子又淘金,所以生存压力应该相对较小,大不了只卖铲子就好了。而且百度经历了PC,移动互联网时代,攒了不少数据。虽然说网上语料大多数都是垃圾,但是垃圾堆里好好洗一洗,优质语料还是比别家的多的。
腾讯(混元)卷大模型我个人觉得没啥优势,但是毕竟国内老大哥的体量摆在那里,可以期待一下未来。
创业公司比较看好:智谱(智谱清言),Moonshot(Kimi月之暗面)和Minimax(海螺AI) 这三家。智谱属于入局比较早的,初期的时候 GLM-130B 在榜上也是很能打的。而且背靠着清华,不愁拿不到订单,活下来才有希望。Moonshot 给人的感觉有点像 Anthropic,大牛挺多,更偏科研一些,但是也有融资压力。希望投资人对这类的好苗子温柔一点,别老想着变现。Minimax 则有点像 Character AI,属于在某个细分领域已经有些成果的公司了。我感觉这家公司就比较务实,有自己的模型,也有自己的产品。虽然产品也不是原创,但是早期腾讯不就是看谁做的好就直接拿过来么? Minimax 后续能成为小腾讯也说不定。
Baichuan(百川) 在最开始的时候优势很大,但是随着一些越来越多的开源,大公司的算力优势已经把 Baichuan 的先发优势抹平甚至超越了,然后还没有云平台,人才储备猜测没有 Moonshot 好,也没有很有竞争力的产品。如果能和一些没有大模型研发能力的云服务平台合作就好了,能够实现双赢。
下面我们使用文心一言(推荐)辅助我们学习:
Eg:已知椭圆r:x\^2/4+y\^2/3=1,直线y=2x+1与椭圆r交于A,B两点,则|AB|的长度是多少,给出python编程计算并可视化的程序,注意不要只给出结果
让我们看看效果:

看起来不错对吗?程序运行结果:
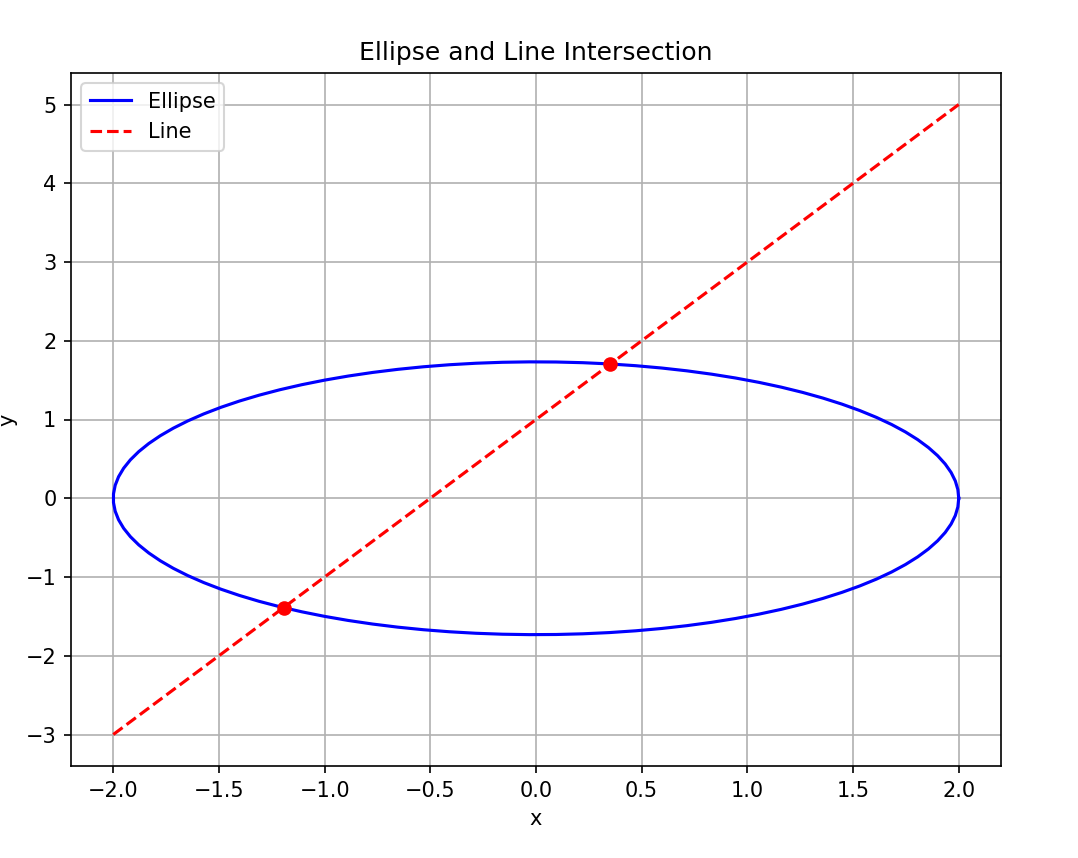

结果是正确的,但是实际上,有时候他并不那么好用,在生成长代码时很容易token到达限制导致停止。如果同学们能魔法上网使用GPT-4,其中内置的mathematica功能就强大的多,甚至在求解过程中发现自己的问题,他会承认错误并改正。
篇幅原因,如果大家喜欢,我会根据大家的意见在下一期出更多的科普和建议,谢谢!




